Τα μεγάλα γλωσσικά μοντέλα (Large Language Models, ή LLM) που είναι ικανά για σύνθετες εργασίες «συλλογισμού» έχουν δημιουργήσει μεγάλες προσδοκίες για τομείς όπως ο προγραμματισμός και η δημιουργική γραφή. Ωστόσο, ο κόσμος των LLM δεν είναι ένας παράδεισος plug-and-play. Υπάρχουν αρκετές προκλήσεις όσον αφορά τη χρηστικότητα, την ασφάλεια και βέβαα τις υπολογιστικές απαιτήσεις. Σε αυτό το άρθρο, θα δούμε -ακροθιγώς- τις δυνατότητες του Llama 2, ενώ παράλληλα θα κάνουμε μια πρώτη εισαγωγή στη ρύθμιση αυτού του LLM μέσω του Hugging Face και των GPU T4 στο Google Colab.
Τι εστί Llama 2
To Llama 2 λοιπόν είναι ένα Μεγάλο Γλωσσικό Μοντέλο ανοιχτού κώδικα, που αναπτύχθηκε από τη Meta σε συνεργασία με τη Microsoft, και έχει τον κάπως βαρύγδουπο στόχο να «επαναπροσδιορίσει» τα πεδία της δημιουργικής Τεχνητής Νοημοσύνης (generative AI) και της κατανόησης της φυσικής γλώσσας. Το Llama 2 δεν είναι απλώς άλλο ένα στατιστικό μοντέλο που εκπαιδεύεται σε terabytes δεδομένων λένε οι δημιουργοί του, είναι η ενσάρκωση μιας φιλοσοφίας που δίνει έμφαση στον ανοικτό κώδικα ως ραχοκοκαλιά της ανάπτυξης της Τεχνητής Νοημοσύνης, ιδίως στον τομέα της δημιουργικής τεχνητής νοημοσύνης.
Το Llama 2 και το βελτιστοποιημένο για διάλογο υποκατάστατό του, το Llama 2-Chat, είναι εξοπλισμένα με έως και 70 δισεκατομμύρια παραμέτρους. Υποβάλλονται σε μια διαδικασία ρύθμισης που έχει σχεδιαστεί για να τα ευθυγραμμίζει στενά με τις ανθρώπινες προτιμήσεις, καθιστώντας τα ασφαλέστερα και αποτελεσματικότερα από πολλά άλλα διαθέσιμα στο κοινό μοντέλα. Αυτό το επίπεδο λεπτομερούς ρύθμισης προορίζεται συχνά για τα κλειστά εμπορικά LLM, όπως το ChatGPT και το BARD, τα οποία όμως δεν είναι διαθέσιμα για δημόσιο έλεγχο ή προσαρμογή.
Μια (μικρή) βουτιά στο Llama 2
Για την εκπαίδευση του μοντέλου Llama 2, χρησιμοποιηθηκε μια αρχιτεκτονική αυτοπαλινδρομικού μετασχηματιστή (transformer), προεκπαιδευμένη σε ένα εκτεταμένο σώμα δεδομένων με αυτοεπίβλεψη, καθώς και ένα πρόσθετο επίπεδο Ενισχυτικής Μάθησης με Ανθρώπινη Ανατροφοδότηση (RLHF) για την καλύτερη «ευθυγράμμιση» με την ανθρώπινη συμπεριφορά και προτιμήσεις. Αυτό είναι υπολογιστικά δαπανηρό, αλλά ζωτικής σημασίας για τη βελτίωση της ασφάλειας και της αποτελεσματικότητας του μοντέλου.
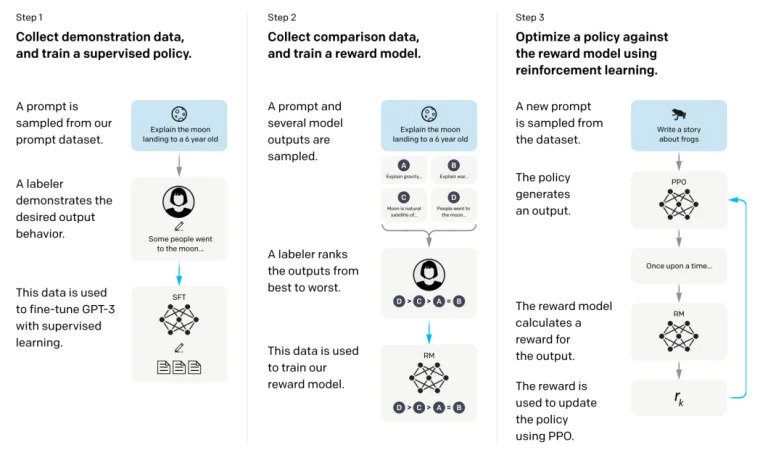
Επειδή όμως όλα αυτά είναι κάπως δυσνόητα και μια εικόνα είναι χίλιες λέξεις, η OpenAI είχε δώσει παλιότερα μια ωραία απεικόνιση η οποία εξηγούσε τις μεθοδολογίες Supervised Fine-Tuning (SFT) και RLHF όπως χρησιμοποιούνταν στο InstructGPT. Το βήμα 1 στην παρακάτω εικόνα εστιάζει στην εποπτευόμενη λεπτομέρεια (SFT), ενώ τα επόμενα βήματα ολοκληρώνουν τη διαδικασία Ενίσχυσης Εκμάθησης από Ανθρώπινη Ανάδραση (RLHF).
Η θεμελιώδης καινοτομία του Llama 2 έγκειται όμως στην προ-εκπαίδευση. Το μοντέλο παίρνει στοιχεία από τον προκάτοχό του, το Llama 1, αλλά εισάγει βελτιώσεις για να αυξήσει τις επιδόσεις του. Ξεχωρίζουν η αύξηση κατά 40% του συνολικού αριθμού των εκπαιδευμένων tokens και η διπλάσια αύξηση του μήκους του πλαισίου (context). Επιπλέον, το μοντέλο αξιοποιεί την προσοχή σε ομαδοποιημένα ερωτήματα (GQA) για να ενισχύσει την επεκτασιμότητα των συμπερασμάτων.
Αν όλα τα παραπάνω σας φαίνονται κινέζικα, και θέλετε να καταλάβετε τι είναι και πως λειτουργούν τα LLM, προτείνουμε να δείτε αυτήν την πολύ καλή διαδραστική παρουσίαση των LLM από την εφημερίδα The Guardian.
Ας δούμε τώρα πως θα αποκτήσετε πρόσβαση στο LLaMa 2.
Από το Meta Git Repository χρησιμοποιώντας το download.sh
- Επισκεφθείτε τον επίσημο ιστότοπο της Meta για το Llama 2 και κάντε κλικ στο 'Download The Model'
- Διαβάστε και αποδεχτείτε τους όρους και τις προϋποθέσεις για να προχωρήσετε.
- Μόλις υποβληθεί η φόρμα, θα λάβετε ένα email από τη Meta με έναν σύνδεσμο για να κατεβάσετε το μοντέλο από το git repository.
- Κλωνοποιήστε το αποθετήριο Git και τρέξτε το αρχείο εντολών που λέγεται download.sh. Αυτό θα σας ζητήσει να πραγματοποιήσετε έλεγχο ταυτότητας χρησιμοποιώντας μια διεύθυνση URL από τη Meta που λήγει σε 24 ώρες. Θα επιλέξετε επίσης το μέγεθος του μοντέλου: 7B, 13B ή 70B.
Από το Hugging Face
- Λήψη email αποδοχής: Αφού αποκτήσετε πρόσβαση από το Meta, μεταβείτε στο Hugging Face.
- Αίτημα πρόσβασης: Επιλέξτε το μοντέλο που επιθυμείτε και υποβάλετε αίτημα για την παροχή πρόσβασης.
- Επιβεβαίωση: Αναμείνατε ένα email με την ένδειξη "χορηγείται πρόσβαση" εντός 1-2 ημερών.
- Δημιουργία διακριτικών πρόσβασης: Πλοηγηθείτε στις 'Ρυθμίσεις' στο λογαριασμό σας στο Hugging Face για να δημιουργήσετε διακριτικά πρόσβασης.
Το Transformers 4.31 είναι πλήρως συμβατό με το LLaMa 2 και δίνει πολλά εργαλεία και λειτουργίες στο οικοσύστημα Hugging Face. Από σενάρια εκπαίδευσης και συμπερασμάτων έως κβαντοποίηση 4 bit με bitsandbyte και την αποδοτική τελειοποίηση παραμέτρων (PEFT), η εργαλειοθήκη είναι εκτεταμένη. Για να ξεκινήσετε, βεβαιωθείτε ότι χρησιμοποιείτε την πιο πρόσφατη έκδοση του Transformers και έχετε συνδεθεί στον λογαριασμό σας στο Hugging Face.
Ακολουθεί ένας απλός οδηγός για να τρέξετε model inference στο LLaMa 2 σε περιβάλλον Google Colab, αξιοποιώντας GPU:
Εγκατάσταση πακέτου
!pip install transformers !huggingface-cli login
Εισάγετε τις απαραίτητες βιβλιοθήκες Python
from transformers import AutoTokenizer import transformers import torch
Αρχικοποίηση του μοντέλου και του Tokenizer
Σε αυτό το βήμα, καθορίστε ποιο μοντέλο Llama 2 θα χρησιμοποιήσετε. Για αυτόν τον οδηγό, χρησιμοποιούμε το meta-llama/Llama-2-7b-chat-hf.
model = "meta-llama/Llama-2-7b-chat-hf" tokenizer = AutoTokenizer.from_pretrained(model)
Ρύθμιση Pipeline
Χρησιμοποιήστε το Hugging Face pipeline για δημιουργία κειμένου με συγκεκριμένες ρυθμίσεις:
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto")
Δημιουργία ακολουθιών κειμένου
Τέλος, εκτελέστε το pipeline και δημιουργήστε μια ακολουθία κειμένου με βάση την εισαγωγή σας:
sequences = pipeline(
'Who are the key contributors to the field of artificial intelligence?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Ενα chatbot για το LLaMa 2
Η Andreessen Horowitz (A16Z) παρουσίασε πρόσφατα ένα νέο chatbot interface, με βάση το Streamlit, κατάλληλο για το Llama 2. Αυτό το περιβάλλον εργασίας που φιλοξενείται στο GitHub, διατηρεί το ιστορικό της συνομιλίας στη συνεδρία και παρέχει την ευελιξία να επιλέξετε από πολλά τελικά σημεία API του Llama 2 που φιλοξενούνται στο Replicate. Αυτός ο σχεδιασμός με επίκεντρο τον χρήστη στοχεύει στην απλοποίηση των αλληλεπιδράσεων με το Llama 2, καθιστώντας το ιδανικό εργαλείο τόσο για τους προγραμματιστές όσο και για τους τελικούς χρήστες. Για όσους ενδιαφέρονται να το δοκιμάσουν αυτό, ένα ζωντανό demo είναι διαθέσιμο στο Llama2.ai.
FAQ: Σε τι διαφέρει το Llama 2 από τα άλλα μοντέλα GPT και τον προκάτοχό του Llama 1;
Ποικιλία στην κλίμακα
Σε αντίθεση με πολλά γλωσσικά μοντέλα που προσφέρουν περιορισμένη επεκτασιμότητα, το Llama 2 σας δίνει ένα σωρό διαφορετικές επιλογές για μοντέλα με ποικίλες παραμέτρους. Το μοντέλο κλιμακώνεται από 7 δισεκατομμύρια έως 70 δισεκατομμύρια παραμέτρους, παρέχοντας έτσι ένα εύρος διαμορφώσεων που ταιριάζουν σε διαφορετικές υπολογιστικές ανάγκες.
Ενισχυμένο μήκος πλαισίου
Το μοντέλο έχει αυξημένο μήκος πλαισίου 4Κ tokens σε σχέση με το Llama 1. Αυτό του επιτρέπει να συγκρατεί περισσότερες πληροφορίες, ενισχύοντας έτσι την ικανότητά του να κατανοεί και να παράγει πιο σύνθετο και εκτεταμένο περιεχόμενο.
Grouped Query Attention (GQA)
Η αρχιτεκτονική χρησιμοποιεί την έννοια της GQA, η οποία έχει σχεδιαστεί για να επιταχύνει τη διαδικασία υπολογισμού της προσοχής μέσω της προσωρινής αποθήκευσης προηγούμενων ζευγών συμβόλων. Αυτό βελτιώνει αποτελεσματικά την επεκτασιμότητα του μοντέλου εξαγωγής συμπερασμάτων για την ενίσχυση της προσβασιμότητας.
Σημεία αναφοράς απόδοσης
Το LLama 2 έχει θέσει νέα πρότυπα στις μετρήσεις επιδόσεων. Όχι μόνο ξεπερνά τον προκάτοχό του, το LLama 1, αλλά προσφέρει επίσης σημαντικό ανταγωνισμό σε άλλα μοντέλα όπως το Falcon και το GPT-3. 5.
Το μεγαλύτερο μοντέλο του Llama 2-Chat, το 70B, ξεπερνά επίσης το ChatGPT στο 36% των περιπτώσεων και ταιριάζει με τις επιδόσεις σε άλλο 31,5% των περιπτώσεων.
Ανοικτός κώδικας: Η δύναμη της κοινότητας
Η Meta και η Microsoft σκοπεύουν το Llama 2 να είναι κάτι περισσότερο από ένα απλό προϊόν- το οραματίζονται ως ένα εργαλείο με γνώμονα την κοινότητα. Η πρόσβαση στο Llama 2 είναι ελεύθερη τόσο για ερευνητικούς όσο και για μη εμπορικούς σκοπούς. Στόχος τους είναι να εκδημοκρατίσουν τις δυνατότητες ΤΝ, καθιστώντας τις προσιτές σε νεοσύστατες επιχειρήσεις, ερευνητές και επιχειρήσεις. Ένα παράδειγμα ανοικτού κώδικα επιτρέπει την "διόρθωση προβλημάτων από το πλήθος" του μοντέλου. Οι προγραμματιστές και οι ηθικολόγοι της Τεχνητής Νοημοσύνης μπορούν να κάνουν δοκιμές αντοχής, να εντοπίζουν τρωτά σημεία και να προσφέρουν λύσεις με επιταχυνόμενο ρυθμό.
Ενώ οι όροι αδειοδότησης για το LLaMa 2 είναι γενικά επιτρεπτικοί, υπάρχουν εξαιρέσεις. Μεγάλες επιχειρήσεις με πάνω από 700 εκατομμύρια μηνιαίους χρήστες, όπως η Google, απαιτούν ρητή εξουσιοδότηση από τη Meta για τη χρήση της. Επιπλέον, η άδεια χρήσης απαγορεύει τη χρήση του LLaMa 2 για τη βελτίωση άλλων γλωσσικών μοντέλων.
Τρέχουσες προκλήσεις με το Llama 2
Γενίκευση δεδομένων: Τόσο το Llama 2 όσο και το GPT-4 μερικές φορές παρουσιάζουν ομοιόμορφα υψηλή απόδοση σε διαφορετικές εργασίες. Η ποιότητα και η ποικιλομορφία των δεδομένων είναι εξίσου καθοριστικής σημασίας με τον όγκο σε αυτά τα σενάρια.
Διαφάνεια μοντέλου: Δεδομένων προηγούμενων αποτυχιών με την τεχνητή νοημοσύνη να παράγει παραπλανητικά αποτελέσματα, η διερεύνηση της λογικής λήψης αποφάσεων πίσω από αυτά τα πολύπλοκα μοντέλα είναι υψίστης σημασίας.
Code Llama – Η τελευταία κυκλοφορία της Meta
Η Meta ανακοίνωσε πρόσφατα το Code Llama, το οποίο είναι ένα μεγάλο γλωσσικό μοντέλο εξειδικευμένο στον προγραμματισμό με μεγέθη παραμέτρων που κυμαίνονται από 7B έως 34B. Παρόμοια με τον διερμηνέα κώδικα ChatGPT, το Code Llama μπορεί να βελτιώσει τις ροές εργασίας των προγραμματιστών και να κάνει τον προγραμματισμό πιο προσιτό. Υποδέχεται διάφορες γλώσσες προγραμματισμού και διατίθεται σε εξειδικευμένες παραλλαγές, όπως το Code Llama-Python για εργασίες που αφορούν ειδικά την Python. Το μοντέλο προσφέρει επίσης διαφορετικά επίπεδα επιδόσεων για την κάλυψη διαφορετικών απαιτήσεων καθυστέρησης. Με ανοιχτή άδεια χρήσης, το Code Llama προσκαλεί την κοινότητα να συνεισφέρει για συνεχή βελτίωση.
- Συνδεθείτε ή εγγραφείτε για να σχολιάσετε