Ξεχάστε για λίγο τις κλασικές βάσεις δεδομένων SQL και τη MySQL. Καιρός να εντρυφήσετε στα μυστικά των NoSQL βάσεων δεδομένων...
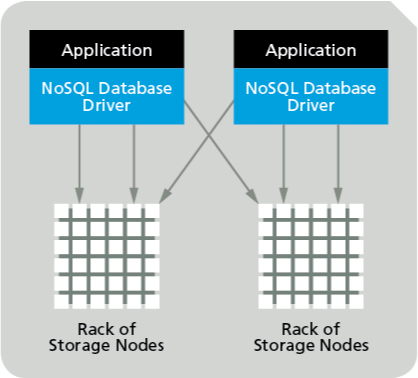
Αρχίζοντας την αναφορά μας στα NoSQL (διαβάζεται Not Only SQL) συστήματα και βάσεις δεδομένων, ας αναφέρουμε (για τους φίλους μας που τώρα αρχίζουν σταδιακά να ασχολούνται με το αντικείμενο) πως πρόκειται για μια ευρεία ομάδα συστημάτων διαχείρισης βάσεων δεδομένων (database management system) που το κύριο χαρακτηριστικό του είναι η μη τήρηση του μοντέλου RDBMS (Relational Database Management System), το οποίο και χρησιμοποιείται «τυφλά» στην συντριπτική πλειοψηφία των περιπτώσεων. Ίσως επίσης παρατηρήσατε πως δεν γίνεται καμία αναφορά στο «τι είναι NoSQL βάσεις». Και αυτό γιατί δεν μπορούμε να δώσουμε έναν σαφή ορισμό να πούμε τί είναι ή τι δεν είναι ένα σύστημα NoSQL, απλά λέμε πως δεν είναι RDBMS και πως χρησιμοποιεί εντελώς διαφορετικό από τον κλασικό τρόπο για την διαχείριση των δεδομένων μέσα στην βάση (data manipulation). Οι NoSQL βάσεις δεδομένων γενικώς δεν χρησιμοποιούν κάποιο δομημένο σύστημα για τα στοιχεία που περιλαμβάνουν, όπως πχ πίνακες, ούτε χρησιμοποιούν κάποια Structured Query Language (SQL) για την διαχείριση των δεδομένων, αλλά χρησιμοποιούν αποκλειστικά non-relational τρόπους οργάνωσης και ανάλυσης των δεδομένων.
Τα NoSQL συστήματα κατά κύριο λόγο είναι βελτιστοποιημένα (optimized) ώστε να ανακτούν και να επισυνάπτουν δεδομένα. Η μειωμένη ευελιξία του χρόνου εκτέλεσης σε σύγκριση με συστήματα SQL (δηλαδή με τα RDBMS) αντισταθμίζεται από την σημαντική αύξηση στην απόδοση (και την επεκτασιμότητα) για ορισμένα μοντέλα δεδομένων. Τα δεδομένα θα μπορούσαν να είναι δομημένα, αλλά αυτό είναι στην πραγματικότητα ασήμαντο καθώς αν κάτι έχει ουσιαστική σημασία στα NoSQL συστήματα αυτό είναι η ικανότητα να αποθηκεύουν και να ανακτούν μεγάλες ποσότητες δεδομένων, «αδιαφορώντας» για τις σχέσεις μεταξύ των στοιχείων αυτών.
Τα βασικά χαρακτηριστικά των NoSQL database systems είναι:
1) Η μη χρήση της SQL ως query language,
2) δεν μπορεί να εγγυηθεί ότι οι διεργασίες στην βάση δεδομένων θα γίνονται αξιόπιστα και 3) έχουν μια ιδιαίτερη αρχιτεκτονική και φιλοσοφία λειτουργίας.
Αναλυτικότερα, τα NoSQL συστήματα αναπτύχθηκαν και εξελίχθηκαν παράλληλα με τις μεγαλύτερες εταιρίες πληροφορικής στον κόσμο, όπως η Google ή η Amazon, που είχαν ανάγκη να διαχειρίζονται έναν τεράστιο όγκο δεδομένων, κάτι στο οποίο δεν βόλευαν τα παραδοσιακά μέχρι τότε συστήματα RDBMS. Τα NoSQL συστήματα έχουν φτιαχτεί έτσι ώστε να μπορούν να διαχειριστούν μεγάλες ποσότητες δεδομένων χωρίς κατ’ανάγκη να διατηρούν μία συγκεκριμένη δομή (schema). Επίσης, οι μέθοδοι υλοποίησης και εφαρμογής τους αξιοποιούν μια αρχιτεκτονική που επιτρέπει (και ίσως διευκολύνει) την κατανεμημένη λειτουργία του συστήματος. Έτσι με αυτόν τον τρόπο το σύστημα μπορεί θεωρητικά να «απογειωθεί» σε επιδόσεις, από την στιγμή που μπορούν να προστεθούν θεωρητικά άπειροι servers όπου κατανεμημένα θα επεξεργάζονται τα δεδομένα του συστήματος. Ακόμη, η ενδεχόμενη αδυναμία λειτουργίας ενός server του συστήματος μπορεί να αντιμετωπισθεί εύκολα. Αυτός ο τύπος βάσεων δεδομένων αναπτύσσεται διαρκώς οριζόντια, καθώς αυξάνονται οι ανάγκες για storage δεδομένων, που συνεχώς πληθαίνουν (data growth), ενώ είναι πιο σημαντικές οι επιδόσεις προσπέλασης των δεδομένων από την συνοχή που παρουσιάζουν.
Αφού είδαμε πιο συγκεκριμένα κάποια στοιχεία σχετικά με την λειτουργία των NoSQL συστημάτων, τώρα θα αναφερθούμε πιο ειδικά στα πλεονεκτήματα τους, σε πρακτικό πια επίπεδο. Αρχικά, παρουσιάζουν μεγάλη «ελαστικότητα» στην βελτίωση της επίδοσης τους. Μάλιστα από την στιγμή που η υλοποίησή τους τις περισσότερες φορές γίνεται σε υποδομές cloud ή σε virtualized environments, συμφέρουν πολύ από οικονομική άποψη, σε αντίθεση με τα κλασικά RDBMS συστήματα. Ειδικότερα, ενώ στα RDBMS συστήματα, όταν θέλουμε να τα βελτιώσουμε, προσθέτουμε περισσότερη μνήμη RΑΜ ή καλύτερους επεξεργαστές στις υποδομές μας, αντίθετα στα NoSQL συστήματα απλά προσθέτουμε κόμβους ώστε να επεξεργάζονται ακόμη περισσότερα δεδομένα ταυτόχρονα. Επίσης, η συντήρηση ενός high-end συστήματος RDBMS που διαχειρίζεται τεράστιο όγκο δεδομένων απαιτεί εξίσου μεγάλο κόστος (κυρίως Database Administrators, που αρχίζουν πια να χάνουν την αξία τους). Αντίθετα, τα NoSQL συστήματα εξ’ορισμού είναι σχεδιασμένα ώστε να απαιτούν τη λιγότερη δυνατή διαχείριση από τον ανθρώπινο παράγοντα, χρησιμοποιώντας μεθόδους όπως automatic repair, data distribution και πιο απλά μοντέλα δεδομένων. Όλα αυτά οδηγούν σε σαφώς μικρότερες ανάγκες για διαχείριση ή βελτιστοποίηση του συστήματος. Επιπλέον, οποιαδήποτε αλλαγή στο μοντέλο δεδομένων ενός συστήματος RDBMS είναι μία διαδικασία που απαιτεί ένα σεβαστό χρονικό διάστημα που η εφαρμογή που στηρίζεται στην συγκεκριμένη βάση δεδομένων θα είναι «κατεβασμένη» (downtime) ή θα μειωθούν σε μεγάλο βαθμό τα επίπεδα λειτουργίας της υπηρεσίας, ενώ ένα NoSQL σύστημα έχει πολύ λιγότερους (έως μηδαμινούς) περιορισμούς σε αυτό το ζήτημα.
Ας δούμε όμως λίγο πιο προσεκτικά ορισμένες λεπτομέρειες για τα NoSQL συστήματα. Εδώ θα πρέπει να αναφερθεί ότι υπάρχουν ορισμένες κατηγορίες για τις NoSQL βάσεις:
1) οι Key-values Stores,
2) οι Column Family Stores ,
3) οι Document Databases και
4) οι Graph Databases.
Η πρώτη κατηγορία, οι key-value stores, δημιουργήθηκαν με κυρίως ιδέα την ύπαρξη ενός hash table όπου υπάρχει ένα μοναδικό κλειδί και ένας δείκτης στοχεύοντας σε ένα συγκεκριμένο στοιχείο. Αυτό το είδος mapping συνήθως συνοδεύεται από μηχανισμους cache, για την καλύτερη απόδοση του συστήματος.
Οι Column family stores βάσεις σχεδιάστηκαν έτσι ώστε να διαχειρίζονται πολύ μεγάλα ποσά δεδομένων που είναι κατανεμημένα σε διάφορους servers. Όπως και στην προηγούμενη κατηγορία, έτσι κι εδώ υπάρχουν συγκεκριμένα κλειδιά (keys) που στοχεύουν όμως σε περισσότερα από ένα στοιχεία. Οι rows εδώ αναγνωρίζονται από ένα μοναδικό row key ενώ οι στήλες είναι οργανωμένες σε column families («οικογένειες στηλών»).
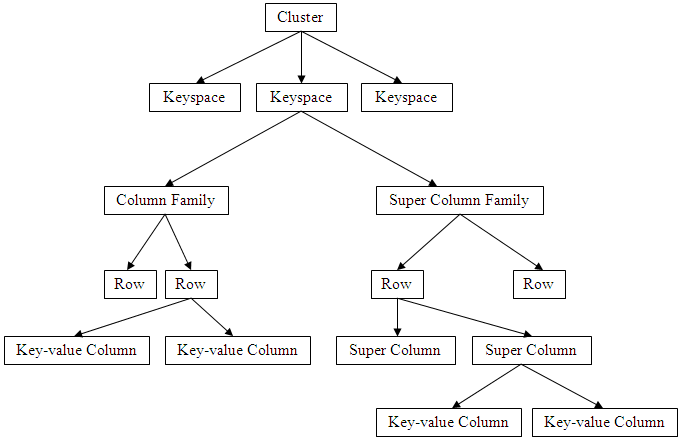
Η επόμενη κατηγορία, των Document databases, είναι όμοιες με τις key-value stores. Τα δεδομένα σε αυτή την περίπτωση είναι οργανωμένα από «συλλογές» key-valued «συλλογών» δεδομένων.
Η τελευταία κατηγορία, αυτή των Graph databases, είναι βασισμένη σε κόμβους (nodes), τις σχέσεις μεταξύ αυτών των κόμβων και τις ιδιότητές τους. Αντί για πίνακες με στήλες και σειρές, εδώ υπάρχει ένα ευέλικτο γραφικό μοντέλο (graph model) που μπορεί να χρησιμοποιηθεί και να αναπτυχθεί παράλληλα σε πολλά μηχανήματα (servers – κόμβους).
Αφού αναφερθήκαμε και στις κατηγορίες των NoSQL συστημάτων , θα κάνουμε και μια αναφορά στις πιο γνωστές και διαδεδομένες βάσεις δεδομένων NoSQL.
1) Cassandra: Η Cassandra είχε δημιουργηθεί από την Facebook και ανήκει πια στα Apache projects. Είναι μια column oriented NoSQL database και ανοικτού κώδικα.
2) Dynamo και SimpleDB: Αποτελούν δημιουργίες της Amazon και η πρώτη είναι η πιο γνωστή Key-Value NoSQL βάση δεδομένων, ενώ η δεύτερη είναι μέρος των Amazon Cloud Services EC2 και S3.
3) BigTable: η BigTable είναι δημιούργημα της Google, και η χρήση της περιορίζεται μόνο μέσω του Google App Engine. Τεχνικά, είναι μια column oriented database κλειστού κώδικα.
4) Neo4J: αποτελεί μια τύπου graph NoSQL database ελεύθερου κώδικα.
5) CouchDB και MongoDB: αυτές οι δύο αποτελούν τις πιο γνωστές open source document oriented NoSQL βάσεις.
Οι περισσότεροι developers αναρωτιούνται πώς μπορούν να συντάξουν ένα query για μία NoSQL βάση καθώς το να υπάρχει αποθηκευμένο σε μία βάση δεν λέει τίποτα από μόνο του αν δεν μπορούμε να το εμφανίσουμε στους end users μέσω μίας πχ web application. Αντίθετα με τις RDBMS βάσεις, εδώ δεν υπάρχει κάποια συγκεκριμένη ξεκάθαρη query language όπως η SQL για την διαχείριση των δεδομένων αλλά αντίθετα η διαχείριση και η εξέταση αυτών των βάσεων είναι “εξαρτημένη” από μοντέλο δεδομένων που χρησιμοποιείται.
Κάποιες NoSQL πλατφόρμες επιτρέπουν την χρήση RESTful μοντέλων διεπαφής με τα δεδομένα ενώ άλλες παρέχουν query APIs. Υπάρχουν και μερικά (δύο για την ακρίβεια) εργαλεία που έχουν αναπτυχθεί με σκοπό την διαχείριση πολλαπλών NoSQL βάσεων δεδομένων, τα οποία προσπαθούν κυρίως να διαχειριστούν NoSQL βάσεις της ίδιας κατηγορίας.
Το ένα από αυτά (και πιο γνωστό) είναι το SPARQL, που απευθύνεται σε graph databases. Παρακάτω σε δύο παραδείγματα θα δούμε πως μπορούμε να ανακτήσουμε το link ενός συγκεκριμένου blogger μέσα σε μία βάση με αποθηκευμένα στοιχεία για blogs και να κάνουμε μία αναζήτηση όλων των ονομάτων που αναφέρονται στο FOAF file του Tim Berners Lee.
FOAF file είναι ο τύπος των αρχείων μέσα στα οποία περιγράφονται οι άνθρωποι και οι σχέσεις τους. Αποτελεί ένα standard RDF λεξιλόγιο , αναγνωρίσιμο δηλαδή τύπο αρχείων από τις NoSQL βάσεις και το SPARQL.
1ο παράδειγμα:
PREFIX foaf: http://xmlns.com/foaf/0.1/ //τυπικός καθορισμός του prefix type SELECT ?url //υπόδειξη ώστε να γίνει επιλογή του URL FROM <bloggers.rdf> //καθορισμός του αρχείου απ’όπου θα γίνει η αναζήτηση. Συγκεκριμένα, είναι το αρχείο που βρίσκονται αποθηκευμένα τα στοιχεία όλων των blogs. WHERE { ?contributor foaf:name "Kostas Livieratos" . //καθορισμός του ονόματος του blogger του οποίου το URL αναζητάται ?contributor foaf:weblog ?url . //επιστροφή του αποτελέσματος }
Ο επόμενος κώδικας θα ισχύει και θα λειτουργεί μόνο αν ορισθεί η διεύθυνση της κάρτας πληροφοριών του Tim Berners Lee στο αρχείο του SPARQL. To FOAF file του Tim Berners Lee βρίσκεται στην διεύθυνση http://dig.csail.mit.edu/2008/webdav/timbl/foaf.rdf και περιλαμβάνει όλα τα διαθέσιμα στοιχεία.
2ο παράδειγμα:
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?name WHERE { ?person foaf:name ?name . }
Εν ολίγοις, τα NoSQL συστήματα βάσεων δεδομένων είναι ιδιαίτερα χρήσιμα όταν εργαζόμαστε με μια τεράστια ποσότητα δεδομένων και η φύση των δεδομένων αυτών δεν απαιτεί ένα σχεσιακό μοντέλο για τη δομή των δεδομένων. Ακόμη, για την διενέργεια ακόμη και ενός (φαινομενικά) απλού query απαιτούνται προγραμματιστικές γνώσεις και έτσι απέχουν ακόμα πολύ από τον αρχικό τους στόχο που είναι να παρέχουν διευκολύνσεις zero-administration (καθώς απαιτούν μεγάλη «προσπάθεια» στο deployment και το maintaining).
Εγκατάσταση και ρύθμιση του Cassandra
Αν έπειτα απ’όλα αυτά σας έπιασε κι εσάς η περιέργεια είτε να ασχοληθείτε είτε να δοκιμάσετε σε κάποιο υπάρχον σύστημά σας κάποιο NoSQL database system, παρακάτω ακολουθούν οδηγίες για το πώς μπορείτε να βάλετε στο (Linux) σύστημά σας ένα από τα πιο αξιόπιστα και γνωστά NoSQL software, το Cassandra (στην συνέχεια ίσως την αναφέρω ως κάτι θηλυκό, για ευνόητους λόγους).
Ξεκινώντας, να πω ότι για να μην «χαθούν» οι πιο αρχάριοι χρήστες, δεν θα αναφερθώ καθόλου σε compiling κλπ που ίσως να ενδιέφερε πιο έμπειρους χρήστες. Αντίθετα, θα κατεβάσουμε την binary έκδοση κατευθείαν.
Κατεβάζουμε λοιπόν την εκτελέσιμη έκδοση του Cassandra project από την επίσημη ιστοσελίδα του [1].
cd /usr/tmp wget http://apache.forthnet.gr/cassandra/1.1.6/apache-cassandra-1.1.6-bin.tar.gz tar –xzvf <filename>
Έπειτα κατεβάζουμε το Java Runtime Environment (JRE) από την επίσημη σελίδα της Oracle, το οποίο είναι απαραίτητο στοιχείο για την λειτουργία του Cassandra, καθώς είναι γραμμένο σε Java [2]. Ανατρέξτε στην τεκμηρίωση της διανομής σας για το πως θα εγκαταστήσετε το JRE.
Αφού τελειώσουμε με αυτή την εγκατάσταση, ήρθε η ώρα για να κάνουμε την παραμετροποίηση. Περιηγούμαστε στον αντίστοιχο φάκελο και επεξεργαζόμαστε το αρχείο storage-conf.xml:
cd /usr/tmp/apache-cassandra-0.5.1/conf nano storage-conf.xml
Εκεί αλλάζουμε το στοιχείο ClusterName σε κάτι που να έχει νόημα για το δικό μας σύστημα και φυσικά τις παραμέτρους CommitLogDirectories, DataFileDirectories, CalloutLocation και StagingFileDirectory στους αντίστοιχους φακέλους που πρόκειται να αποθηκευτούν οι βάσεις δεδομένων.
Πρίν ξεκινήσετε την Cassandra στον server σας, καλό είναι να σετάρετε την μεταβλητή JAVA_HOME, το path δηλαδή που βρίσκονται εγκατεστημένα τα Java JRE bin αρχεία. Αυτό μπορείτε να το κάνετε κάπως έτσι, αξιοποιώντας την εντολή set.
set JAVA_HOME=/path/to/java/jdk7_64
Σε περίπτωση που εμφανιστούν αναπάντεχα errors ύστερα από την τελευταία εντολή (όπως έγινε και με τον υποφαινόμενο), τότε κατά πάσα πιθανότητα κάτι δεν πάει καλά με το σετάρισμα του JAVA_HOME, οπότε και θα πρέπει να αφιερώσετε λίγο χρόνο για να δείτε ποιο είναι το σωστό path για την Java. Μην ξεχνάτε οτι το NoSQL σύστημα Cassandra είναι γραμμένο σε Java και απαιτεί την ύπαρξη του JRE για να λειτουργήσει.
Αφού ολοκληρώσουμε και αυτό, με cd .. επιστρέφουμε στον προηγούμενο φάκελο και εκεί με την εντολή bin/cassandra-f ανοίγουμε την Cassandra.
Τώρα έχουμε ήδη έτοιμο έναν κόμβο που τρέχει την Cassandra. Αξιοποιώντας ένα ακόμα open-source εργαλείο του Apache Foundation, το Thrift (το οποίο είναι ένα software framework για cross-language services development και υποστηρίζεται από το δεδομένο project), θα μπορέσουμε να «εγκαθιδρύσουμε» την επικοινωνία μας (χρησιμοποιώντας PHP ή JAVA) με την Cassandra, δημιουργώντας records που απλά τα καλούμε από τον κόμβο που θέλουμε. Για να λειτουργήσει, πρέπει να κατεβάσουμε και να εγκαταστήσουμε μια βιβλιοθήκη της C++, την Boost [3].
cd /usr/ports/devel/boost make all make install cd /usr/ports/devel/automake110 make all make install /usr/ports/devel/autoconf262 make all make install
Και αφού κατεβάσουμε το Thrift από την επίσημη ιστοσελίδα [4] στο path /usr/tmp/ το εγκαθιστούμε:
wget "https://dist.apache.org/repos/dist/release/thrift/0.9.0/thrift-0.9.0.tar.gz" tar -xvfz thrift-0.9.0* cd thrift-0.9.0 ./bootstrap.sh ./configure --with-boost=/usr/local make make install
Οπότε τώρα έχουμε ολοκληρώσει την ρύθμιση της Cassandra στο cluster μας. Κάλλιστα, όπως και κάθε άλλο NoSQL σύστημα, μπορεί να λειτουργεί σε έναν μόνο κόμβο. Όμως, τα NoSQL συστήματα έχουν ουσιαστικά σχεδιαστεί για να λειτουργούν παράλληλα στους διαφορετικούς κόμβους ενός cluster και όχι μεμονωμένα. Αυτό άλλωστε είναι και ένα από τα βασικότερα πλεονεκτήματά τους. Ακολουθεί λοιπόν ένα παράδειγμα με το πώς μπορούμε να ρυθμίσουμε την Cassandra να τρέχει σε διαφορετικούς κόμβους του cluster.
Βασικά, όλες οι αλλαγές και οι ρυθμίσεις γίνονται στο αρχείο /etc/cassandra/conf/cassandra.yaml, το οποίο μπορείτε να το επεξεργαστείτε με τον επεξεργαστή κειμένου της επιλογής σας και να προσθέσετε περιεχόμενο σαν αυτό που ακολουθεί, ώστε να ικανοποιεί τις συνθήκες του συστήματός σας:
node0 cluster_name: 'my_cluster' #υποδεικνύει το όνομα του cluster σας initial_token: 0 #ο πρώτος κόμβος έχει πάντα token 0 seed_provider: - seeds: "172.168.0.0,172.168.0.3" listen_address: 172.168.0.0 rpc_address: 0.0.0.0 endpoint_snitch: RackInferringSnitch #προσδιορίζει τον τύπο και το είδος του δικτύου node1 cluster_name: 'my_cluster' initial_token: <token> seed_provider: - seeds: "172.168.0.0,172.168.0.3" listen_address: 172.168.0.1 rpc_address: 0.0.0.0 endpoint_snitch: RackInferringSnitch node2 cluster_name: 'my_cluster' initial_token: <token> seed_provider: - seeds: "172.168.0.0,172.168.0.3" listen_address: 172.168.0.2 rpc_address: 0.0.0.0 endpoint_snitch: RackInferringSnitch
Στα σχόλια του παραδείγματος παραπάνω, αναφέρθηκε ότι ο πρώτος κόμβος έχει πάντα token ίσο με 0. Οι υπόλοιποι κόμβοι όμως δεν έχουν token 0, αλλά διαφορετικό, ανάλογα με το μέγεθος του cluster που διαθέτετε.
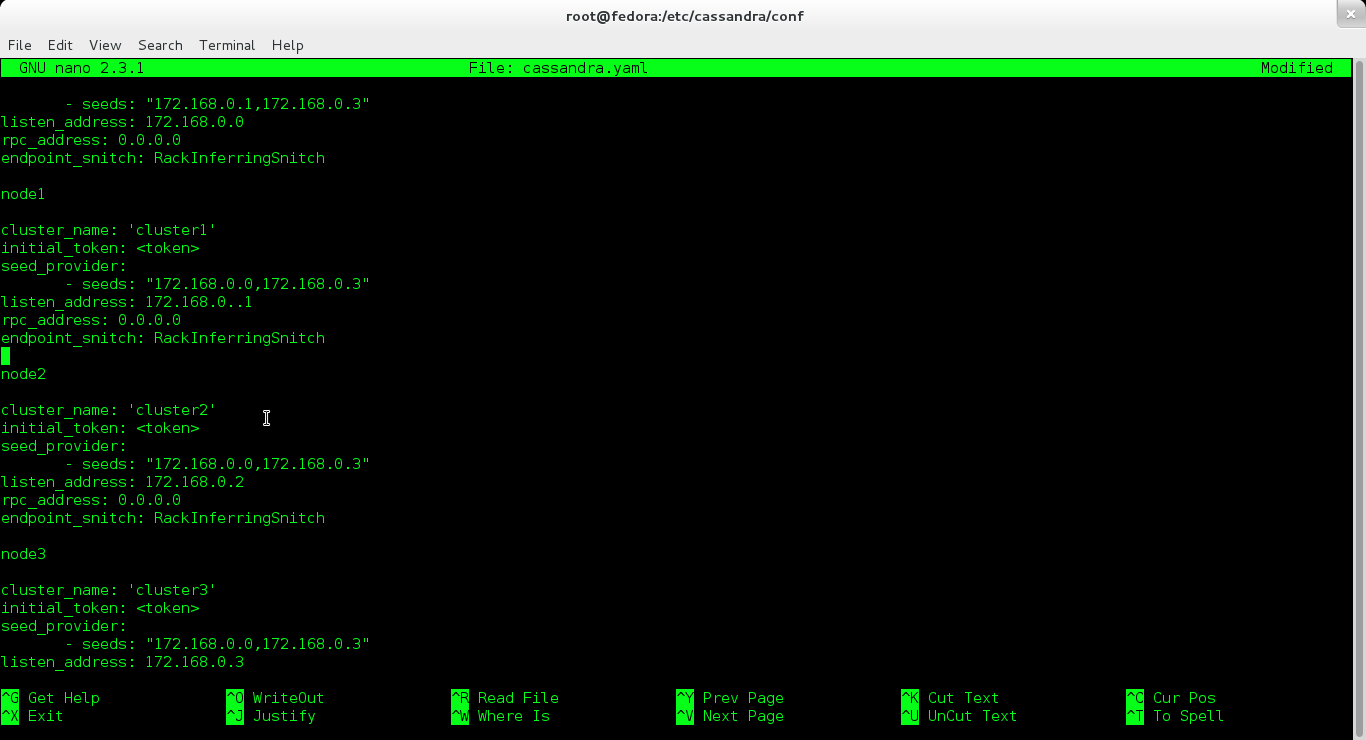 Τροποποιούμε το cassandra.yaml αρχείο σύμφωνα με τις ανάγκες μας.
Τροποποιούμε το cassandra.yaml αρχείο σύμφωνα με τις ανάγκες μας.
Παρακάτω είναι ένα python script με το οποίο μπορείτε πανεύκολα και γρήγορα να υπολογίσετε το token του κάθε κόμβου.
#! /usr/bin/env python
import sys
if (len(sys.argv) > 1):
num=int(sys.argv[1])
else:
num=int(raw_input("Ποσοι κομβοι υπαρχουν στο cluster σας? "))
for i in range(0, num):
print 'token %d: %d' % (i, (i*(2**127)/num))Πιο συγκεκριμένα, αντιγράψτε το σε έναν φάκελο της επιλογής σας (στον υπολογιστή σας) και στο τερματικό πληκτρολογήστε
cd /path/pou/antigrapsate/to/script/ chmod a+x token_calc.py #το κάνετε executable ./token_calc #το εκτελείτε
Όταν το εκτελέσετε, το μόνο που θα σας ζητηθεί είναι να εισάγετε τον αριθμό των κόμβων και αυτόματα θα σας επιτρέψει τις τιμές των token, για τον κάθε κόμβο. Αντικαταστήστε τις τιμές και προκειμένου να ενεργοποιηθούν οι καινούριες σας ρυθμίσεις, επανεκκινήστε τον server. Έτοιμοι!
Συνοψίζοντας, καλό είναι να πούμε πως σύμφωνα με επίσημα στατιστικά στοιχεία, 44% των business IT professionals δεν έχουν καν ακούσει για τα NoSQL συστήματα ενώ μόλις το 1% σκοπεύουν στο άμεσο μέλλον να το ενσωματώσουν στο περιβάλλον εργασίας τους, τα projects τους κτλπ. Αυτό σημαίνει ότι αυτό το σύστημα δεν έχει σε καμία περίπτωση την απήχηση που έχει το RDBMS στον κόσμο μας ακόμα. Αυτό ενδεχομένως και να οφείλεται στο ότι τα συστήματα RDBMS υπάρχουν από τα τέλη της δεκαετίας του ’70 και έχουν μέχρι τώρα συνδεθεί άρρηκτα με την ανάπτυξη των συστημάτων αποθήκευσης δεδομένων στις επιχειρήσεις. Σίγουρα θα χρειαστεί να γίνει η μετάβαση προς αυτό κάποια στιγμή λόγω των υπέρογκων δεδομένων που έχει κάθε σοβαρή (!) επιχείρηση. Όπως αναφέρουν χαρακτηριστικά και ειδικοί του κλάδου, «NoSQL systems are the future for any informatics incorporation».
Σύνδεσμοι
[1] Cassandra: http://cassandra.apache.org/download
[2] Oracle Java: http://goo.gl/qTfgc
[3] Boost: http://goo.gl/OmdYF
[4] Thrift: http://thrift.apache.org/download
Ποιος ειναι ο Κωνσταντίνος Λιβιεράτος
 Ο Κώστας είναι φοιτητής και του αρέσει ο προγραμματισμός και το IT administration
Ο Κώστας είναι φοιτητής και του αρέσει ο προγραμματισμός και το IT administration
- Συνδεθείτε ή εγγραφείτε για να σχολιάσετε